The concept of cloud started in the early days of the internet where people would shorthand the entire internet as a cloud of other computers and servers available on the internet to do your work and not be limited to the memory and processor of the machine on your desk. In many ways, cloud computing is a metaphor for the internet, the increasing movement of computing data resources on the web. Cloud computing represents a new tipping point for the value of network computing. It delivers higher efficiency, massive scalability, and faster, easier software development. Cloud computing comes into focus only when you think about what IT always needs: a way to increase capacity or add capabilities on the fly without investing in new infrastructure, training new personnel, or licensing new software. Cloud computing encompasses any Subscription-based or pay-per-use service that, in real time over the Internet, extends IT’s existing capabilities.
Introduction
Cloud computing refers to any situation in which computing is done in a remote location (out in the clouds) rather than your portable device or desktop wherein the computing power is tapped over an internet connection. At a basic level cloud computing is simply a means of delivering IT resources as services. Almost all IT resources can be delivered as a cloud service: applications, compute power, storage capacity, networking, programming tools, communication services even collaboration tools. Cloud computing began as large-scale internet service providers such as Google, Amazon, and others built out their infrastructure. A new architecture emerged: A massively scaled, horizontally distributed system resources, abstracted as virtual IT services and managed as continuously configured pooled resources. This new model was applied to internet services.
2. Comparing different types of Computing
2.1 Cloud computing vs. Utility computing:
Utility computing often requires cloud-like infrastructure; its focus is on the business model on which provide the computing services are based. Simply put, utility computing service is the one in which customer services computing resources from a service provider (hardware or software) and pay for the utility. In cloud computing, a single user at any given point only gets a small portion of the utility or the cloud.
2.2 Cloud computing vs. Grid computing:
Grid computing is applying the resources of many computers in a network to a single problem at a time usually to a scientific or technical problem that requires a great number of computer processing and a large amount of data whereas cloud computing is about lots of small allocation requests.
2.3 Cloud computing vs. Autonomic computing:
The autonomic computing system is a self-managing computing system, capable of handling the need for increasingly complex tasks while keeping itself in check. Cloud computing relies on many features of autonomic computing, however, the idea behind cloud computing is more ambitious i.e. extending the power by spreading out the work.
3. The architecture of Cloud Computing
When talking about a cloud computing system, it is helpful to divide it into three sections: the front end, the central system, and the back end. They connect to each other through a network, usually the Internet via a set of protocols. The front end is the side the computer user, or client. The back end is the “cloud” section of the system.
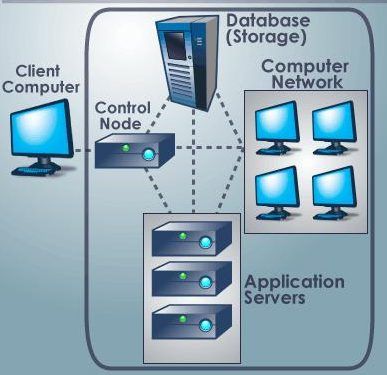
The front end includes the client’s computer and the application required to access the cloud computing system. This could include services like accessing social networking accounts via web browsers, Salesforce (CRM application), Zuora (subscription business model), etc.
A central server administers the system, monitoring traffic and client demands to ensure everything runs smoothly. It follows a set of rules called protocols and uses integration software called middleware. Middleware allows networked computers to communicate with each other via web services or REST APIs. Middleware software can run on-premise or on the cloud. The best example for an on-premise middleware is Tibco software and for cloud-based, there are many like Oracle Fusion Middleware, Mulesoft, Red Hat JBoss Fusee, etc. Most of the cloud-supported software support on-premise too.
On the back end of the system are the various computers, servers, and data storage systems that create the “cloud” of computing services. In theory, a cloud computing system could include practically any computer program you can imagine, from data processing to video games. Usually, each application will have its own dedicated server.
So when a customer creates an account in the Salesforce system (front-end application) the account details are sent to Middleware software like Mulesoft via a set of protocols. Next, the account details are pushed end systems like other CRM systems, cloud database, etc.
In the initial days, only the front-end system was available on the cloud and middleware would run on-premise. This architecture would slower the data processing. In recent days, middleware systems are also being pushed to the cloud to achieve better results in data processing and fasten up response time to end users.
To secure client’s data, a cloud computing system must make a copy of all its clients’ information and store it on different servers as a backup. The copies enable the central server to access backup machines to retrieve data that otherwise would be unreachable.
Vendors who provide cloud services
- Amazon is the first one to provide true cloud computing resources with Amazon Web Services. AWS offers a wide variety of services to individuals and organizations. When it comes to cloud service providers, AWS dominates everyone with 34% of all cloud followed by which are Microsoft, Google, and IBM with 11%, 8%, 6% of services respectively. (ref: wiki)
- Google launched its cloud computing offering named Apps engine
- Microsoft has its own cloud computing services named Azure.
- IBM has its own cloud computing offering named Blue cloud.
- Red Hat also provides cloud computing using Amazon Web Services on the open source Red Hat Enterprise Linux operating system which uses instances of Red Hat Enterprise Linux running on the Amazon Elastic Compute Cloud (EC2) web service.
4. Services of cloud computing

- Software as a Service(SaaS):
It is at the highest layer and features a complete application offered as a service, on-demand, via multi-tenancy, meaning a single instance of the software runs on the provider’s infrastructure and serves multiple client organizations. SaaS represents a number of licensing and pricing models for the vendors to choose from that includes pay-as-you-go, subscription-based, revenue-based, transaction-based and other. Some even go as far as offering complete services free of charge preferring to monetize with ads only.
- Platform as a Service(PaaS):
The middle layer is the encapsulation of a development environment abstraction and the packaging of a payload of services. PaaS is an integrated platform to build, test and deploy custom applications.
- Hardware as a Service(HaaS):
HaaS is at the lowest level and is a means of delivering basic storage and compute capabilities as standardized services over the network. Servers, storage systems, switches, routers, and other systems are pooled (through virtualization) to handle specific types of workloads from batch processing to server augmentation during peak loads.
5. Different modes of Cloud Computing
Public:
Public clouds are run by third parties, and jobs from many different customers may be mixed together and the servers, storage systems, and other infrastructure within the cloud. End users don’t know who else’s job may be running on the server, network, or disk as their own jobs.
Private:
Private clouds are a good option for companies dealing with data protection and service-level issues. Private clouds are on-demand infrastructure owned by a single customer who controls which applications run and where. They own the server, network, and disk and can decide which users are allowed to use the infrastructure.
Hybrid:
Hybrid clouds combine public and private cloud models. You own parts and share other parts, though in a controlled way. Hybrid clouds offer the promise of on-demand, externally provisioned scale, but add the complexity of determining how to distribute applications across these environments.
Related Read:
Cloud Computing vs. Distributed Computing: Know the Differences
Snowflake and Other Top Cloud Computing Service Providers
Trending IPaaS Services Available In Market
6. Uses and applications of Cloud Computing
The applications of cloud computing are practically limitless. With the right middleware, a cloud computing system could execute all the programs a normal computer could run. Potentially, everything from generic word processing software to customized computer programs designed for a specific company could work on a cloud computing system.
Why would anyone want to rely on another computer system to run programs and store data? Here are just a few reasons:
- Clients would be able to access their applications and data from anywhere at any time. They could access the cloud computing system using any computer linked to the Internet. Data wouldn’t be confined to a hard drive on one user’s computer or even a corporation’s internal network.
- It could bring hardware costs down. Cloud computing systems would reduce the need for advanced hardware on the client-side. You wouldn’t need to buy the fastest computer with a high memory because the cloud system would take care of those needs for you. Instead, you could buy an inexpensive computer terminal. The terminal could include a monitor, input devices like a keyboard and mouse, and just enough processing power to run the middleware necessary to connect to the cloud system. You wouldn’t need a large hard drive because you’d store all your information on a remote computer.
- Corporations that rely on computers have to make sure they have the right software in place to achieve goals. Cloud computing systems give these organizations company-wide access to computer applications. The companies don’t have to buy a set of software or software licenses for every employee. Instead, the company could pay a metered fee to a cloud computing company.
- Servers and digital storage devices take up space. Some companies rent physical space to store servers and databases because they don’t have it available on site. Cloud computing gives these companies the option of storing data on someone else’s hardware, removing the need for physical space on the front end.
- Corporations might save money on IT support. Streamlined hardware would, in theory, have fewer problems than a network of heterogeneous machines and operating systems.
If the cloud computing system’s back end is a grid computing system, then the client could take advantage of the entire network’s processing power. Often, scientists and researchers work with calculations so complex that it would take years for individual computers to complete them. On a grid computing system, the client could send the calculation to the cloud for processing. The cloud system would tap into the processing power of all available computers on the back end, significantly speeding up the calculation.
7. Limitations
Cloud computing with all its benefits also has its own set of limitations that restrict enterprises from moving their applications to the cloud. Some of these limitations are:
- Customization is nearly impossible
- Scalability problems with sequential processing
- Data privacy issues because of the common resources
- Lack of high-speed Internet connectivity
- Cost surpasses traditional hosting in case of very high usage
Conclusion
The cloud has been a revolution in terms of response time to the client. It abstracts the software application platform from the underlying hardware infrastructure, freeing developers and users from becoming locked into specific hardware. We can foresee that many applications which we use in our daily life would be deployed on cloud to better the consumer-to-provider relationship.
can i take this topic for my mtech seminar topic and paper oresentation als.
Hi Gautam,
Yes. You can take it up. Do add all the latest details in computing.
Well..but I am not sure what makes this cloud computing even better!! I want to know its disadvantages as well as advantages.I hope I get a reply post.
Hi Lin,
Please go through following post for advantages of cloud computing
https://krazytech.com/technical-papers/grid-and-cloud-computing-an-overview