Artificial intelligence workloads are expanding rapidly in scale and complexity, driving the adoption of specialized AI accelerators across modern data centers. While raw compute capability is essential, overall accelerator performance increasingly depends on how efficiently data moves between processing elements, memory, and storage. Without an optimized communication fabric, even high-performance AI chips can experience latency, congestion, and underutilized compute resources. Network-on-Chip (NoC) interconnects address these challenges by enabling scalable, high-bandwidth, and low-latency communication within AI accelerators.
Achieving optimal AI accelerator performance requires a balanced approach that considers hardware architecture, workload distribution, memory access behavior, and interconnect design. NoC interconnects support parallel data transfers, reduce contention, and enable advanced routing techniques that improve throughput and energy efficiency. When properly designed and tuned, NoC architectures allow AI systems to execute large models faster, scale efficiently, and operate more reliably under heavy workloads.
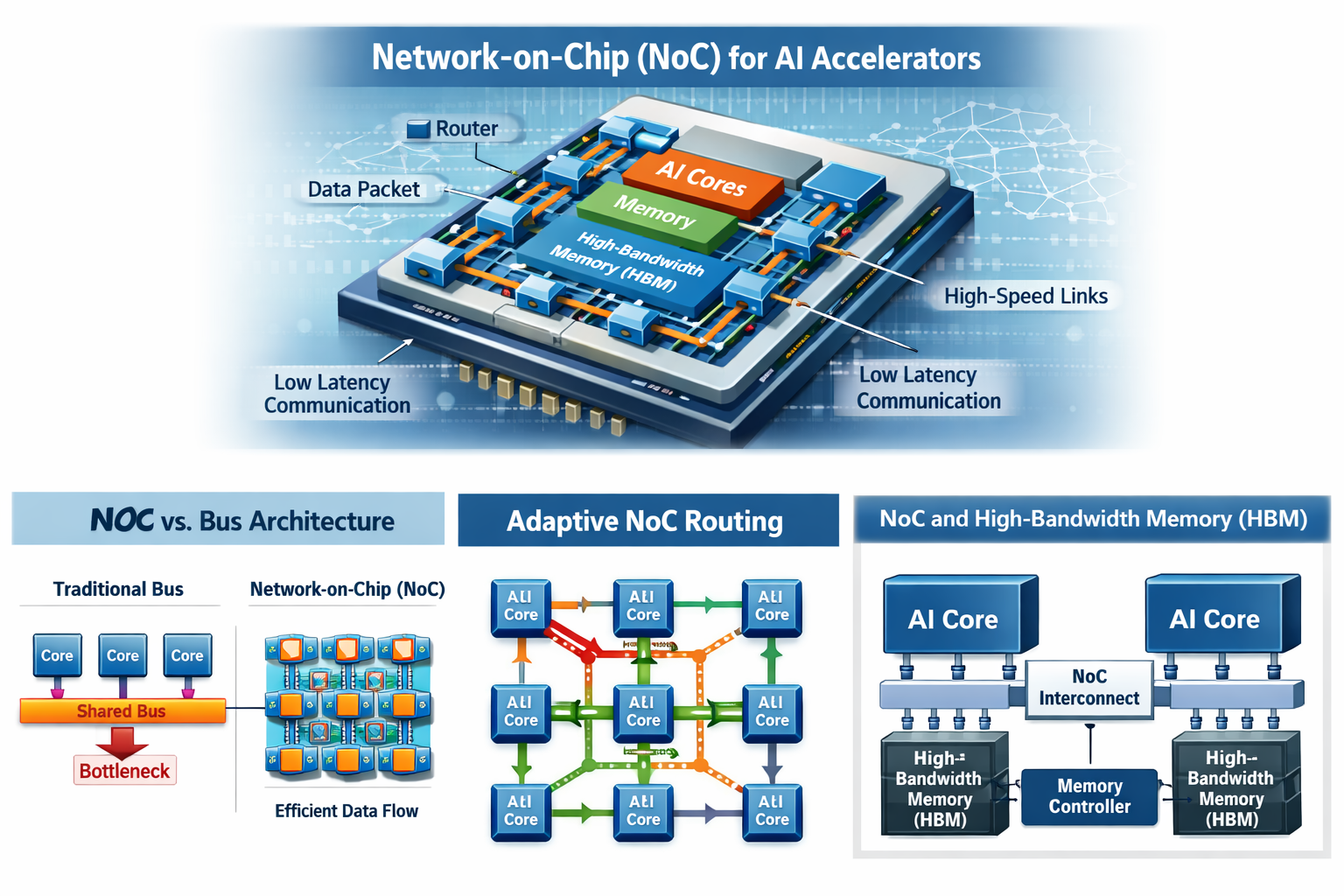
Understanding NoC Interconnect Architecture
NoC interconnects are designed to replace traditional bus-based communication mechanisms used in earlier multi-core processors. Shared buses often become bottlenecks as the number of processing elements increases. In contrast, NoC architectures rely on a structured network of routers and links that connect processing cores, memory controllers, and accelerator components. This approach enables multiple data transfers to occur simultaneously, reducing contention and improving overall system utilization.
Effective workload mapping is critical to maximizing Network-on-Chip performance. By assigning AI workloads to processing cores in a way that aligns with efficient communication paths, developers can ensure consistent data flow and minimize network congestion. Proper mapping is particularly important for AI inference and training workloads, where delays in data movement can significantly impact overall performance.
The topology of a NoC interconnect plays a key role in determining system efficiency. Common topologies such as mesh, torus, and tree-based designs offer different trade-offs in latency, bandwidth, scalability, and power consumption. Selecting the appropriate topology depends on factors such as core count, workload communication patterns, and performance targets. Early design decisions around topology help maximize throughput while keeping energy usage under control.
Improving Data Routing Efficiency
Routing efficiency directly impacts the performance of AI accelerators. Routing algorithms determine how data packets travel between processing elements within the NoC. Static routing follows predefined paths, while adaptive routing dynamically adjusts routes based on real-time network congestion and workload demands. Adaptive routing is especially effective in Artificial intelligence workloads where different phases of computation activate different subsets of cores.
Scheduling mechanisms further enhance routing performance. Techniques such as time-division multiplexing and priority-based routing ensure that latency-sensitive operations are completed without interference from lower-priority traffic. This is particularly important for AI workloads with sequential or dependent operations, where delays in one stage can propagate through the entire computation pipeline. Optimized routing and scheduling strategies help deliver predictable performance and sustained accelerator throughput.
Enhancing Memory Access Performance
Memory access is one of the most common performance bottlenecks in AI accelerator systems. Operations such as matrix multiplications, tensor transformations, and convolutional neural network processing require continuous access to large volumes of data. NoC interconnects enable efficient sharing of memory resources among multiple processing cores, reducing idle time caused by memory access delays.
Integrating high-bandwidth memory with low-latency NoC communication paths ensures that processing elements receive data at a rate that sustains peak computational performance. Additional techniques such as memory partitioning and data locality optimization further reduce access latency. By keeping frequently accessed data closer to the compute cores, NoC architectures minimize data movement, lower energy consumption, and improve overall system efficiency.
Improving Energy Efficiency in AI Accelerators
Energy efficiency is a major concern in AI accelerator design due to the high power consumption and heat generation associated with large-scale AI workloads. Inefficient data movement across the interconnect can significantly increase power usage. NoC interconnects help reduce energy consumption by minimizing unnecessary data transfers and optimizing routing paths.
Dynamic voltage and frequency scaling is another effective technique for improving energy efficiency within NoC architectures. When certain routers or links are lightly utilized, power levels can be adjusted dynamically without impacting performance. This approach reduces operational costs in data center environments and helps extend the lifespan of accelerator hardware by lowering thermal stress.
Supporting Scalability and Future AI Workloads
As AI models continue to grow in size and complexity, scalability has become a fundamental requirement for accelerator platforms. NoC interconnects provide the flexibility needed to scale AI accelerators through modular architectures and expandable core and memory configurations. This allows designers to increase processing capacity without redesigning the entire communication infrastructure.
Scalable NoC designs also ensure that future AI workloads can fully benefit from advances in hardware technology. As data-intensive models become more common, efficient communication between processing elements becomes increasingly critical. Planning for scalability at the design stage enables AI accelerators to remain competitive and deliver high performance across evolving workloads.
Monitoring and Optimizing NoC Performance
Continuous monitoring of NoC performance is essential for maintaining optimal system behavior. Telemetry and profiling tools can track key metrics such as latency, bandwidth utilization, and network congestion. These insights allow engineers to identify performance bottlenecks and adjust routing strategies or workload placement accordingly.
Simulation and modeling tools further support NoC optimization by enabling designers to evaluate different topologies, routing algorithms, and traffic patterns before deployment. This proactive approach helps ensure that the selected interconnect configuration delivers optimal performance for the target AI workloads. Ongoing monitoring and optimization keep the interconnect efficient and reliable throughout the system’s operational lifecycle.
Conclusion
Optimizing AI accelerator performance with NoC interconnects requires a holistic strategy that spans architecture design, routing efficiency, memory access optimization, energy management, and scalability planning. Well-designed NoC interconnects reduce latency, increase throughput, and enable AI accelerators to handle increasingly complex workloads with improved efficiency and reliability.
By leveraging advanced NoC design techniques and continuous performance optimization, data centers can unlock the full potential of AI accelerators. Network-on-Chip interconnects are not just communication mechanisms but foundational components that support the next generation of scalable, high-performance, and energy-efficient AI computing systems.