Have you ever wished to find someone’s contact information without asking them directly? Or you’ve wanted to learn more about a person before agreeing to meet them. You aren’t alone.
Today, many people desire to know more about someone so they don’t have to wait for them to come over and introduce themselves. With People Search Engine, you can accomplish that and lots more! Read on to find out interesting details about it!
What is a People Search Engine?
A people search engine is the same as a regular search engine, but instead of searching for websites, it searches for information about people. So if you wanted to find someone’s address, phone number, email address, or social media profile, you could use some effective deep data finder.
People’s search engines can be extremely useful, but they can also be dangerous. That’s because they make it easy for anyone to find personal information about you with just a few clicks. So if you’re not careful about what information you put online, it could end up in the right person’s hands.
Basic Functionality of a People Search Engine
1. You can use a people search engine to find long-lost friends or relatives
You can use a people search engine to find out how many results come up for your name. For example, if you type in “John Smith,” you might be surprised to see how many other John Smiths are out there!
2. You can use a people search engine to find out if someone has a criminal record
People’s Search Engines can be used for good as well as bad. For example, they’ve been used by law enforcement to track down criminals and by private detectives to help locate missing persons.
3. You can use a People Search Engine to screen People Before First Time Meetings
You can use a people search engine to find someone’s age, employment history, and more.
Some people have even started using people lookup to screen potential dates or business partners. What is more interesting is that you can use a people search engine to check if someone is married or divorced.
5 Fun Facts about People Search Engines
Here are five fun facts about people search engines:
- People search engines are also known as people finders or people directories.
- More than 2 billion people have their data listed in a people search engine.
- The first people search engine was launched in 1994 and was called “Four11” but later acquired by Yahoo in 1997.
- You can use these engines to find more than someone’s contact information or learn all about them even if you have never met them.
- Due to how people access, collect, and store data, People search engines have been criticized by privacy advocates for violating users’ privacy rights.
Suggested Read:
Introduction to Search Engines
How does Google search engine work?
Learn to build a Search Engine using AngularJS
Where to Find People Search Engines?
Social media has made it much easier to discover who knows whom and even which acquaintances have common interests and views. And that is why there are people search engines – sometimes it’s not enough to know what school they went to or what company they work at.
The idea of these websites is that they allow users to search for anyone in any place by their name or other identifying details. These sites also let you see where they schooled or their past employers. Even if someone blocks their profile from view, there may be other ways of tracking them down through publicly available information like real estate records or voter registration lists.
People search engines are different from regular search engines like Google or Bing. Regular search engines index websites and webpages, while people search engines index people. This makes people searching much more effective at finding information about people. Some of the most popular ones include
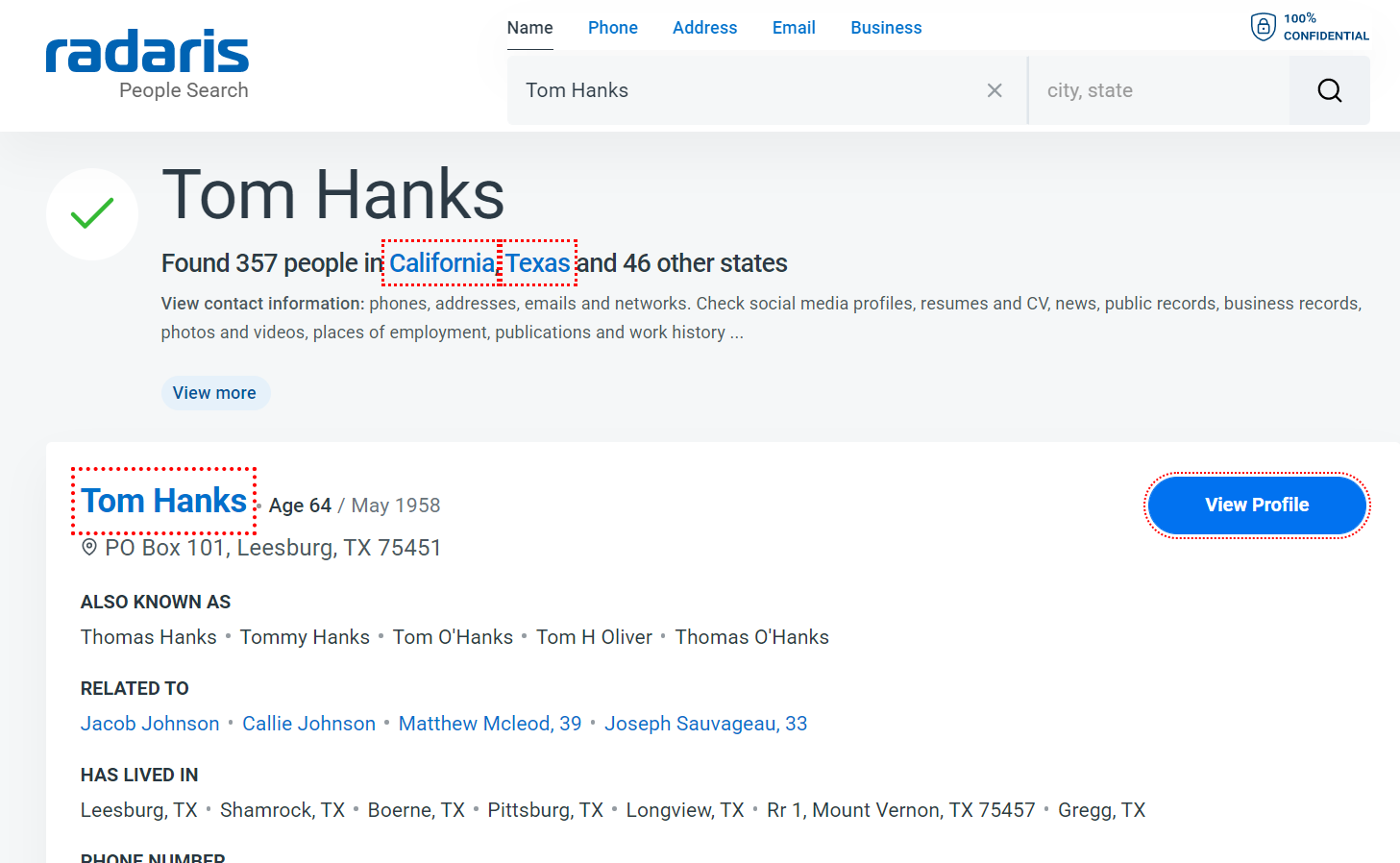
1. Radaris
Radaris is a distinctive provider of public records that has surpassed the requirements of those looking for public documents for more than ten years. Radaris.com offers free profiles of every person in the nation that incorporate public records with social media and other internet mentions, unlike any other public records search engine.
Radaris thoroughly searches through more than 594 million records in order to analyze its people data. With 183 million distinct names in its database, Radaris’ quick person search is trusted to be more precise.
2. Information.com
Information.com makes it easy to find out as much about someone as you can, quickly and easily. Their people search will pull up all available public records about someone, including their criminal records, current and past addresses, every phone number they have, all their email addresses, their job history, and their relatives or associates.
It also brings up someone’s social media accounts, as well as their dating profiles. In addition, you can find every profile they have with every alternate phone number, email, or name they use. Information.com keeps their databases current, so their results are typically accurate and up-to-date
3. Pipl
Rapid identity verification and in-depth investigation are made simple using Pipl.
A robust online identity can be created from as little as one piece of information, such as a phone number, delivery address, social media username, or email address. This will save your team hours of research time and enable better decision-making.
Pipl SEARCH presents research facts and insights on a single page, along with identity trust factors organized for quick identity verification.
4. Spokeo
Here is another means to find people! Spokeo is quite popular in the US since it is free. From a wide range of open internet and offline sources, Spokeo collects and organizes enormous amounts of data about individuals. Quickly gathered public data is provided in an organized, logical, and simple-to-understand way.
You may quickly identify practically any one of the 300 million people who call the United States home using Spokeo’s ground-breaking people finder. You can use Spokeo to locate a long-lost friend or a loved one by inputting their full name, email address, or phone number.
Spokeo lets you choose what information you are specifically interested in before displaying the search results:

5. ZoomInfo
ZoomInfo was developed primarily to assist users in finding accurate, trustworthy information on individuals. Similar to other search engines, the service scours the web for information but concentrates on personal data. ZoomInfo combines data about people from many sources using a combination of artificial intelligence and natural language processing algorithms, gradually constructing online resumes that include career information, educational background, and other specifics.
Conclusion
If you’re looking for someone, chances are that you’ll find them through a people search engine. You’ll be able to easily access the person’s social media profiles, criminal records, marriage status, and more with this deep data finder right away!
Remember to try out a few different People Search Engines until you find the one that works best for you!