Cloud computing has become a foundational technology in today’s digital landscape, transforming how individuals, businesses, and governments access and manage IT resources. At its core, cloud computing refers to the delivery of computing services—such as servers, storage, databases, networking, software, analytics, and intelligence – over the Internet (“the cloud”) to offer faster innovation, flexible resources, and economies of scale.
The concept of the “cloud” originated during the early days of the internet, when network diagrams often represented the internet as a cloud symbol—illustrating a complex network of remote servers. The idea was simple: instead of relying solely on the memory and processing power of a local device, users could offload tasks to powerful remote servers. Over time, this concept evolved into what we now call cloud computing – a transformative model that allows users to access computing power, storage, and applications from virtually anywhere.
Cloud Computing: A Shift in IT Paradigms
Cloud computing represents a major shift in how we think about IT. Traditionally, organizations had to invest heavily in on-premises infrastructure, purchase software licenses, and maintain large IT teams to manage everything. Today, cloud computing offers an on-demand, scalable, and cost-effective alternative.
This model is designed to meet IT needs such as increased capacity, improved scalability, and faster deployment—all without the need for upfront investment in hardware or software. Whether you’re a startup looking to deploy an app quickly or an enterprise managing global infrastructure, cloud services allow you to scale resources up or down based on demand, pay only for what you use, and streamline your operations.
Pay-As-You-Go: The Utility Model of Cloud
One of the defining features of cloud computing is its utility-based pricing model. Much like how you pay for electricity or water, cloud providers charge users based on actual consumption. This subscription-based or pay-per-use approach not only reduces operational costs but also increases flexibility and efficiency.
Major cloud providers—such as Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP), and others—offer a wide range of cloud-based services, including Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS). These models enable users to choose exactly the services they need, when they need them.
2. Comparing different types of Computing
2.1 Cloud computing vs. Utility computing:
Utility computing focuses on the business model of delivering computing services, where customers access hardware or software resources provided by a service provider and pay only for what they use—similar to paying for utilities like electricity or water. While utility computing often relies on cloud-based infrastructure, the key distinction lies in the pricing and service model. Cloud computing, on the other hand, emphasizes flexible and scalable access to computing resources over the internet, where individual users typically consume only a portion of the overall infrastructure at any given time.
2.2 Cloud computing vs. Grid computing:
Grid computing involves pooling the resources of multiple computers across a network to work on a single, large task—typically scientific or technical in nature – that demands significant processing power and data handling. In contrast, cloud computing is designed to handle many smaller, independent tasks or service requests, offering on-demand resource allocation for a wide range of applications and users.
2.3 Cloud computing vs. Autonomic computing:
The autonomic computing system is a self-managing computing system, capable of handling the need for increasingly complex tasks while keeping itself in check. Cloud computing relies on many features of autonomic computing; however, the idea behind cloud computing is more ambitious i.e., extending the power by spreading out the work.
To effectively deploy and maintain these systems, professionals can take Network and Troubleshooting Courses to develop hands-on skills in diagnosing connectivity issues, optimizing performance, and resolving latency, security gaps, and protocol mismatches. You’ll learn methodologies for fixing network problems, improving efficiency, and managing bandwidth, while gaining experience in configuring routers, switches, and firewalls to enhance reliability and productivity in cloud architectures.
3. The architecture of Cloud Computing
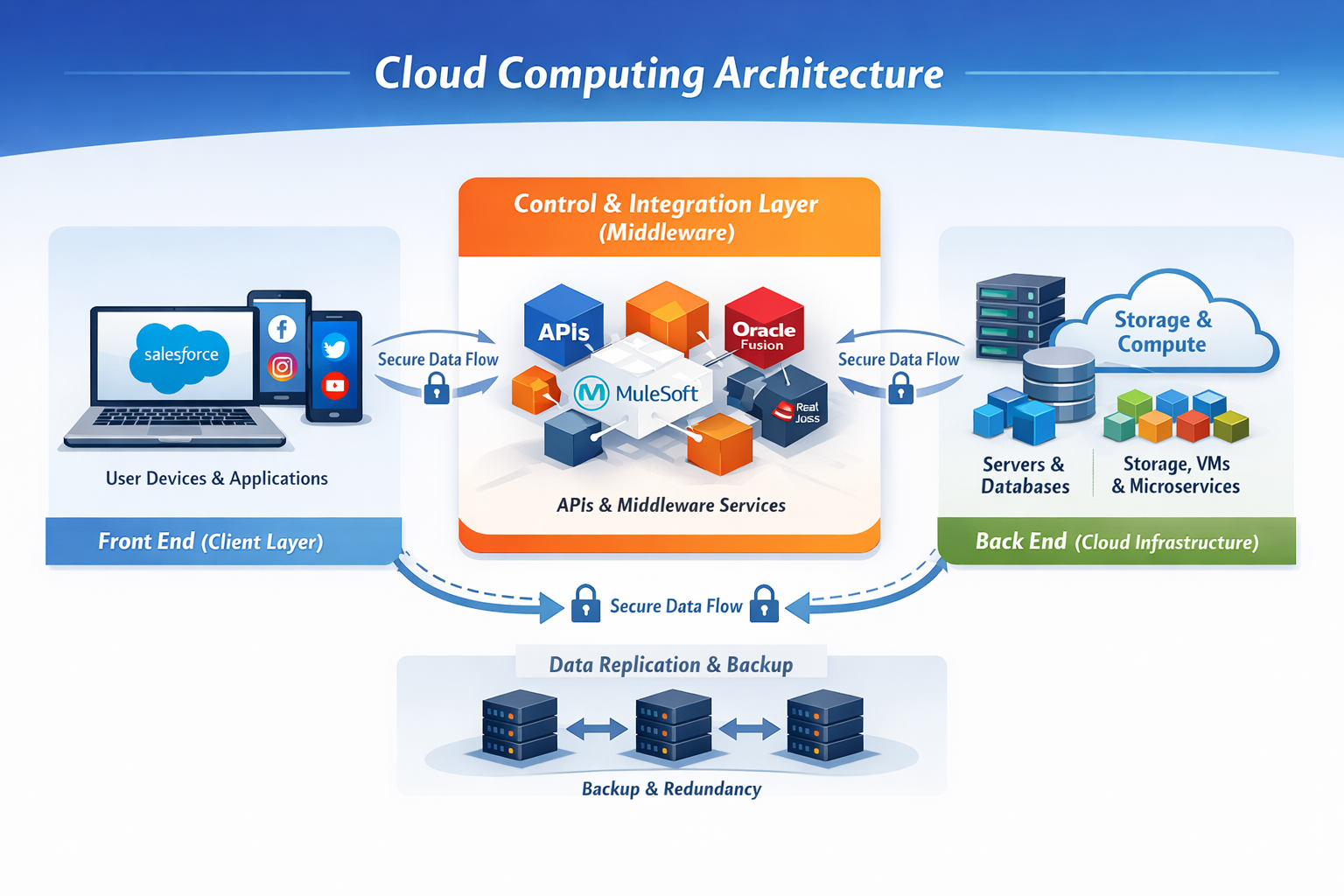
A cloud computing system is typically organized into three logical layers: the front end, the control and integration layer, and the back end. These layers communicate with each other over a network—most commonly the Internet—using standardized protocols and APIs.
Front End (Client Layer)
The front end represents the user-facing side of cloud computing. It includes client devices (such as desktops, laptops, tablets, or mobile phones) and the applications or interfaces used to access cloud services.
This can range from a simple web browser to full-featured enterprise applications.
Common examples include accessing social media platforms through a browser, using CRM systems like Salesforce, or managing subscription-based services through platforms such as Zuora. From the user’s perspective, all interactions happen at this layer, without any visibility into the underlying infrastructure.
Control & Integration Layer (Middleware and Orchestration)
At the center of the architecture lies the control and integration layer, which is responsible for managing traffic, enforcing security, orchestrating workflows, and integrating multiple systems.
This layer relies on middleware, APIs, and messaging services to enable seamless communication between applications.
Middleware acts as the bridge between front-end applications and back-end systems, allowing data to flow through web services, REST APIs, event streams, or message queues.
Historically, middleware was deployed on-premise, but modern architectures increasingly favor cloud-native integration platforms.
Examples include traditional on-premise solutions like Tibco, as well as cloud and hybrid platforms such as Oracle Fusion Middleware, MuleSoft, and Red Hat JBoss Fuse. Most modern middleware solutions now support both cloud and on-premise deployments, enabling flexible hybrid architectures.
Back End (Cloud Infrastructure Layer)
The back end forms the actual “cloud” and consists of servers, virtual machines, containers, databases, storage systems, and networking components. This layer is where data is processed, stored, and managed at scale.
In modern cloud environments, applications are no longer tied to a single dedicated server. Instead, they often run as distributed, microservices-based workloads, dynamically scaling based on demand. This design improves performance, availability, and fault tolerance.
End-to-End Data Flow Example
When a customer creates an account in a front-end application such as Salesforce, the request is transmitted securely via APIs to the middleware layer. The middleware validates, transforms, and routes the data to downstream systems—such as other CRM platforms, ERP systems, or cloud databases—ensuring consistency across the enterprise ecosystem.
Data Security and Reliability
To protect client data, cloud computing systems implement robust security and resilience mechanisms. Data is routinely replicated across multiple servers and geographic locations. These backups ensure high availability and allow systems to recover quickly in the event of failures, outages, or network disruptions.
Vendors who provide cloud services
- Amazon is the first one to provide true cloud computing resources with Amazon Web Services. AWS offers a wide variety of services to individuals and organizations. When it comes to cloud service providers, AWS dominates everyone with 34% of all cloud followed by which are Microsoft, Google, and IBM with 11%, 8%, 6% of services respectively. (ref: wiki)
- Google launched its cloud computing offering named Apps engine
- Microsoft has its own cloud computing services named Azure.
- IBM has its own cloud computing offering named Blue cloud.
- Red Hat also provides cloud computing using Amazon Web Services on the open source Red Hat Enterprise Linux operating system which uses instances of Red Hat Enterprise Linux running on the Amazon Elastic Compute Cloud (EC2) web service.
4. Services of cloud computing

Cloud computing services are generally categorized into three main models based on how much control the user has over applications and infrastructure: SaaS, PaaS, and IaaS.
Software as a Service (SaaS)
SaaS delivers fully functional applications over the internet, accessible through a web browser or a lightweight client. The software runs on the provider’s infrastructure and follows a multi-tenant model, where a single application instance serves multiple customers securely.
Pricing is flexible and may include subscription-based, pay-as-you-go, usage-based, or freemium models. Users do not need to manage updates, infrastructure, or maintenance.
Platform as a Service (PaaS)
PaaS provides a ready-to-use development and deployment environment for building, testing, and running applications. It abstracts infrastructure management and offers tools such as runtimes, databases, middleware, and DevOps pipelines.
This model enables faster development, easier scaling, and supports modern cloud-native and microservices-based applications.
Infrastructure as a Service (IaaS)
IaaS offers core computing resources such as virtual machines, storage, and networking on demand. Physical infrastructure is virtualized and shared across users, allowing organizations to scale resources dynamically while retaining control over operating systems and applications.
It is ideal for flexible workloads, disaster recovery, and handling peak demand.
5. Different modes of Cloud Computing
Public:
Public clouds are run by third parties, and jobs from many different customers may be mixed together and the servers, storage systems, and other infrastructure within the cloud. End users don’t know who else’s job may be running on the server, network, or disk as their own jobs.
Private:
Private clouds are a good option for companies dealing with data protection and service-level issues. Private clouds are on-demand infrastructure owned by a single customer who controls which applications run and where. They own the server, network, and disk and can decide which users are allowed to use the infrastructure.
Hybrid:
Hybrid clouds combine public and private cloud models. You own parts and share other parts, though in a controlled way. Hybrid clouds offer the promise of on-demand, externally provisioned scale, but add the complexity of determining how to distribute applications across these environments.
Related Read:
Cloud Computing vs. Distributed Computing: Know the Differences
Snowflake and Other Top Cloud Computing Service Providers
Trending IPaaS Services Available In Market
6. Uses and applications of Cloud Computing
The applications of cloud computing are virtually unlimited. With modern cloud platforms, APIs, and integration layers, organizations can run almost any type of workload in the cloud—from basic office productivity tools to highly specialized, enterprise-grade applications. Today, cloud systems support business operations, software development, data analytics, artificial intelligence, and large-scale scientific research.
Anywhere, Anytime Access
One of the biggest advantages of cloud computing is universal accessibility. Users can securely access applications and data from anywhere, at any time, using any internet-connected device. Information is no longer tied to a single computer or a company’s internal network, enabling remote work, collaboration, and real-time data sharing across geographies.
Reduced Hardware and Infrastructure Costs
Cloud computing significantly lowers the need for powerful client-side hardware. Since storage and processing happen in the cloud, users can work with lightweight devices that only need enough capability to connect to cloud services. This reduces upfront hardware investment, eliminates large local storage requirements, and extends the lifespan of end-user devices.
Scalable Software Usage and Licensing
For organizations, cloud computing simplifies software management. Instead of purchasing and maintaining licenses for every employee, companies can adopt usage-based or subscription-based models. Cloud platforms allow applications to be deployed centrally and scaled up or down based on demand, improving cost efficiency and operational flexibility.
Optimized Data Storage and Space Management
Traditional servers and data centers require physical space, power, and cooling. Cloud computing removes this burden by allowing organizations to store data on remote, highly available infrastructure. This eliminates the need for on-site server rooms and enables rapid scaling without physical constraints.
Lower IT Maintenance and Support Overhead
With cloud-managed infrastructure and automated updates, organizations can reduce the complexity of IT operations. Standardized environments, centralized monitoring, and provider-managed security updates result in fewer system issues and lower support and maintenance costs.
High-Performance Computing and Advanced Workloads
Cloud platforms excel at handling compute-intensive workloads. Tasks such as big data processing, machine learning training, simulations, and scientific research can leverage distributed and parallel computing across thousands of cloud servers. What once took months or years on a single machine can now be completed in hours or days using elastic cloud resources.
7. Limitations
Despite its many advantages, cloud computing also presents certain limitations that can influence an organization’s decision to migrate applications to the cloud. While many of these challenges have reduced over time, they remain important considerations.
Limited Customization and Control
Cloud platforms are built on standardized architectures to support scale and multi-tenancy. As a result, deep customization at the infrastructure or platform level is often limited, especially in managed services. Organizations with highly specialized or legacy requirements may find it difficult to tailor cloud environments beyond provider-defined configurations.
Performance Constraints for Sequential Workloads
Although cloud systems scale extremely well for parallel processing, workloads that rely heavily on sequential or tightly coupled processing may not always achieve optimal performance. Latency and resource abstraction can impact applications that are not designed for distributed execution.
Data Privacy and Compliance Concerns
Cloud environments rely on shared infrastructure, which can raise concerns around data privacy, regulatory compliance, and data residency. Organizations handling sensitive or regulated data must ensure strong governance, encryption, and compliance controls, which can add complexity to cloud adoption.
Dependence on Reliable Internet Connectivity
Cloud services require consistent, high-speed internet access. In regions with unstable or limited connectivity, application performance and availability can be affected, making cloud solutions less reliable than on-premise systems in such scenarios.
Cost Challenges at Scale
While cloud computing reduces upfront infrastructure costs, expenses can exceed traditional hosting models for continuously high or poorly optimized workloads. Without proper monitoring and cost management, long-running compute, storage, and data transfer usage can lead to unexpected spending.
Conclusion
The cloud has been a revolution in terms of response time to the client. It abstracts the software application platform from the underlying hardware infrastructure, freeing developers and users from becoming locked into specific hardware. We can foresee that many applications which we use in our daily life would be deployed on cloud to better the consumer-to-provider relationship.
can i take this topic for my mtech seminar topic and paper oresentation als.
Hi Gautam,
Yes. You can take it up. Do add all the latest details in computing.
Well..but I am not sure what makes this cloud computing even better!! I want to know its disadvantages as well as advantages.I hope I get a reply post.
Hi Lin,
Please go through following post for advantages of cloud computing
https://krazytech.com/technical-papers/grid-and-cloud-computing-an-overview
Comments are closed.