Apache Hadoop is a core part of the computing infrastructure for many web companies, such as Facebook, Amazon, LinkedIn, Twitter, IBM, AOL, and Alibaba. Most of the Hadoop framework is written in Java language, some part of it in C language and the command line utility is written as shell scripts. In this post, I have covered what is Apache Hadoop and explained the architecture of Hadoop.
What is Hadoop?
Hadoop is an open source framework by Apache Software Foundation and known for writing and running distributed applications that process large amounts of data. It is well suited for voluminous data processing like searching and indexing in the huge data set.
Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Notch, an open source web search engine, itself a part of the Lucene project. Hadoop’s accessibility and simplicity give it an edge overwriting and running large distributed programs. On the other hand, its robustness and scalability make it suitable for even the most demanding jobs at Amazon and Facebook. These features make Hadoop popular in both academia and industry.
What is Big Data?
We all must agree that we live in the age of data. People go on clicking pictures on their cell phones, text friends, update their Facebook status, leave comments around the web, upload videos, send emails, click on ads, and so forth. It’s not easy to measure the total volume of data stored electronically, but an International Data Corporation (IDC) estimate put the size of the “digital universe” at 0.18 zettabytes in 2006 and is forecasting a tenfold growth by 2011 to 1.8 zettabytes. We are not sure about the recent records but we can speculate that there has been another tenfold growth by now. A zettabyte is 10^21 bytes, or equivalently one million petabytes, or one billion terabytes. That’s roughly the same order of magnitude as one disk drive for every person in the world. Thus big data is a term applied to data sets whose size is beyond the ability of commonly used software tools to capture, manage, and process the data within a tolerable elapsed time.
The exponential growth of data presented challenges to cutting-edge businesses such as Google, Facebook, Amazon, and Microsoft. They needed to go through terabytes and petabytes of data to figure out which websites were popular, what books were in demand, and what kinds of ads appealed to people. Existing tools were becoming inadequate to process such large data sets. Google was the first to publicize MapReduce – a system they had used to scale their data Processing needs. This system aroused a lot of interest because many other businesses were facing similar scaling challenges, and it wasn’t feasible for everyone to reinvent their own proprietary tool. Doug Cutting saw an opportunity and led the charge to develop an open source version of this MapReduce system called Hadoop. Soon after, Yahoo, rallied around to support this effort.
Introduction to Apache Hadoop
Consider the example of Facebook, Facebook data has grown up to 600TB/day by 2014 and in future shall produce data of a much higher magnitude. They have many web servers and huge MySQL servers to hold user data.
Now, to run various reports on these huge data For example ratio of men vs. women users for a period, No of users who commented on a particular day. The solution for this requirement they had scripts written in Python which uses ETL processes. But as the size of data increased to this extent these scripts did not work.
Hence their main aim at this point of time was to handle data warehousing and their home ground solutions were not working. Dealing with “Big Data” requires – inexpensive, reliable storage and a new tool for analyzing structured and unstructured data. This is when Hadoop came into the picture.
Hadoop includes the Hadoop Distributed File System (HDFS) and MapReduce. It is not possible for storing a large amount of data on a single node, therefore Hadoop uses a new file system called HDFS which split data into many smaller parts and distribute each part redundantly across multiple nodes. MapReduce is a software framework for the analysis and transformation of very large data sets. Hadoop uses MapReduce function for distributed computation.
MapReduce programs are inherently parallel. Hadoop takes advantage of data distribution by pushing the work involved in the analysis to many different servers. Each server runs the analysis on its own block from the file. Results are combined into single result after analyzing each piece. MapReduce framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
Key distinctions of Hadoop are that it is
- Accessible: Hadoop runs on large clusters of commodity machines or on cloud computing services such as Amazon’s Elastic Compute Cloud (EC2), Amazon Elastic MapReduce process data stored in S3
- Robust: Because it is intended to run on commodity hardware, Hadoop is architected with the assumption of frequent hardware malfunctions. It can gracefully handle most such failures.
- Scalable: Hadoop scales linearly to handle larger data by adding more nodes to the cluster.
- Simple: Hadoop allows users to quickly write efficient parallel code.
Hadoop Architecture:
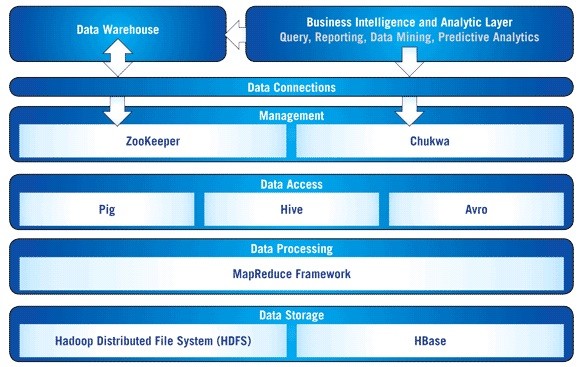
The Hadoop architecture system consists of the following components:
HBase: A distributed, column-oriented database. HBase uses HDFS for its underlying storage and supports both batch-style computations using MapReduce and point queries (random reads). HBase features compression, in-memory operation, and Bloom filters on a per-column basis as outlined in the original Big Table paper. Tables in HBase can serve as the input and output for MapReduce jobs run in Hadoop. HBase is not a direct replacement for a classic SQL database, although recently its performance has improved, and it is now serving several data-driven websites, including Facebook’s Messaging Platform.
HDFS: A distributed filesystem that runs on large clusters of commodity machines.
MapReduce: MapReduce is a functional programming paradigm that is well-suited to handling parallel processing of huge data sets distributed across a large number of computers, or in other words, MapReduce is the application paradigm supported by Hadoop and the infrastructure presented in this article. MapReduce, as its name implies, works in two steps:
Avro: is the serialization framework created by Doug Cutting, the creator of Hadoop. With Avro, we can store data and read it easily with various programming languages. It is optimized to minimize the disk space needed by our data and it is flexible – after adding or removing fields to our data we can still keep reading files previous to the change.
Hive: A distributed data warehouse. Hive manages data stored in HDFS and provides a query language based on SQL for querying the data. Hive looks very much like a traditional database code with SQL access. However, because Hive is based on Hadoop and MapReduce operations, there are several key differences. The first is that Hadoop is intended for long sequential scans, and because Hive is based on Hadoop, you can expect queries to have very high latency (many minutes). This means that Hive would not be appropriate for applications that need very fast response times, as you would expect with a database such as DB2. Finally, the Hive is read-based and therefore not appropriate for transaction processing that typically involves a high percentage of write operations.
Pig: A data flow language and execution environment for exploring very large datasets. Pig runs on HDFS and MapReduce clusters. The pig was initially developed at Yahoo to allow people using Hadoop to focus more on analyzing large data sets and spend less time having to write mapper and reducer programs. Pig is made up of two components: the first is the language itself, which is called PigLatin and the second is a runtime environment where PigLatin programs are executed.
Chukwa: Chukwa is a data collection and Analysis Framework that works with Hadoop to process and analyze the huge logs generated. It is built on top of the Hadoop Distributed File System (HDFS) and Map Reduce Framework. It is a highly flexible tool that makes Log analysis, processing, and monitoring easier, especially while handling Distributed File Systems like Hadoop.
ZooKeeper: ZooKeeper is an open source Apache project that this information in local log files. A very large Hadoop cluster can be supported by multiple ZooKeeper servers (in this case, a master server synchronizes the top-level servers). Each client machine communicates with one of the ZooKeeper servers to retrieve and update its synchronization information.
Within ZooKeeper, an application can create what is called a znode. The znode can be updated by any node in the cluster, and any node in the cluster can register to be informed of changes to that znode. Using this znode infrastructure, applications can synchronize their tasks across the distributed cluster by updating their status in a ZooKeeper znode, which would then inform the rest of the cluster of a specific node’s status change. This cluster-wide status centralization service is essential for management and serialization tasks across a large distributed set of servers.
Sqoop: Using Hadoop for analytics and data processing requires loading data into clusters and processing it in conjunction with other data that often resides in production databases across the enterprise. Loading bulk data into Hadoop from production systems or accessing it from map reduce applications running on large clusters can be a challenging task. This is where Apache Sqoop fits in. Sqoop allows easy import and export of data from structured data stores such as relational databases, enterprise data warehouses.
What happens underneath the covers when you run Sqoop is very straightforward. The dataset being transferred is sliced up into different partitions and a map-only job is launched with individual mappers responsible for transferring a slice of this dataset. Each record of the data is handled in a type-safe manner since Sqoop uses the database metadata to infer the data types.
There are some logging platforms to consolidate logs of the applications running on different servers or on the cloud. With Papertrail, you can consolidate your logs in one place with a cloud-hosted log management service that takes typically only minutes to set up.
Conclusion
When big software vendors like Facebook, IBM, Yahoo were struggling to find a solution to deal with the voluminous data, Hadoop is the only technology which offered a moderate solution. Apache Hadoop has become a necessary tool to tackle big data. As the world is turning digital, we would definitely come across more and more data and need to think of a more simplified solution to handle growing big data.
Good morning sir….u r Really doing a great job by sharing your knowledge….iam a second year student in the stream of computer science and engineering i want best technical ppt presentation sir can u please help me
Thank you Ramya.
You may like following:
Role of nanobots in medical procedures
Brain computer interface
sir…..do hadoop technology comes under in the recent developments…..and i need to give a paper presenation in my college……which one do u prefer hadoop or 5g technology…..???
Hi Praveen,
5G is something upcoming.
Hadoop has been there for several years but it’s still hot in the market.
5G definitely has more weight-age because of wider audience base and trending technology. Many things are unclear still here.
The decision is up to you.
Sir I need top relevant to big data except hadoop
Hi,
Only Apache Hadoop is famous when you talk about big data.
You can also use Hive, HBase individually to deal with the big data.
Comments are closed.